第17天:Python 之引用
1. 引用简介与工具引入
Python 中对于变量的处理与 C 语言有着很大的不同,Python 中的变量具有一个特殊的属性:identity,即“身份标识”。这种特殊的属性也在很多地方被称为“引用”。
为了更加清晰地说明引用相关的问题,我们首先要介绍两个工具:一个Python的内置函数:id();一个运算符:is;同时还要介绍一个sys模块内的函数:getrefcount()。
1.1 内置函数id()
id(object)
Return the “identity” of an object. This is an integer which is guaranteed to be unique and constant for this object during its lifetime. Two objects with non-overlapping lifetimes may have the same `id()`[1] value.
返回值为传入对象的“标识”。该标识是一个唯一的常数,在传入对象的生命周期内与之一一对应。生命周期没有重合的两个对象可能拥有相同的
id()返回值。
CPython implementation detail: This is the address of the object in memory.
CPython 实现细节:“标识”实际上就是对象在内存中的地址。
——引自《Python 3.7.4 文档-内置函数-id()[2]》
换句话说,不论是否是 CPython 实现,一个对象的id就可以视作是其虚拟的内存地址。
1.2 运算符is
| 运算 | 含义 |
|---|---|
| is | object identity |
即
is的作用是比较对象的标识。
——引自《Python 3.7.4 文档-内置类型[3]》
1.3 sys模块函数getrefcount()函数
sys.getrefcount(object)
Return the reference count of the object. The count returned is generally one higher than you might expect, because it includes the (temporary) reference as an argument to `getrefcount()`[4].
返回值是传入对象的引用计数。由于作为参数传入
getrefcount()的时候产生了一次临时引用,因此返回的计数值一般要比预期多1。——引自《Python 3.7.4 文档-sys模块——系统相关参数及函数[5]》
此处的“引用计数”,在 Python 文档[6]中被定义为“对象被引用的次数”。一旦引用计数归零,则对象所在的内存被释放。这是 Python 内部进行自动内存管理的一个机制。
2. 问题示例
C 语言中,变量代表的就是一段固定的内存,而赋给变量的值则是存在这段地址中的数据;但对 Python 来说,变量就不再是一段固定的地址,而只是 Python 中各个对象所附着的标签。理解这一点对于理解 Python 的很多特性十分重要。
2.1 对同一变量赋值
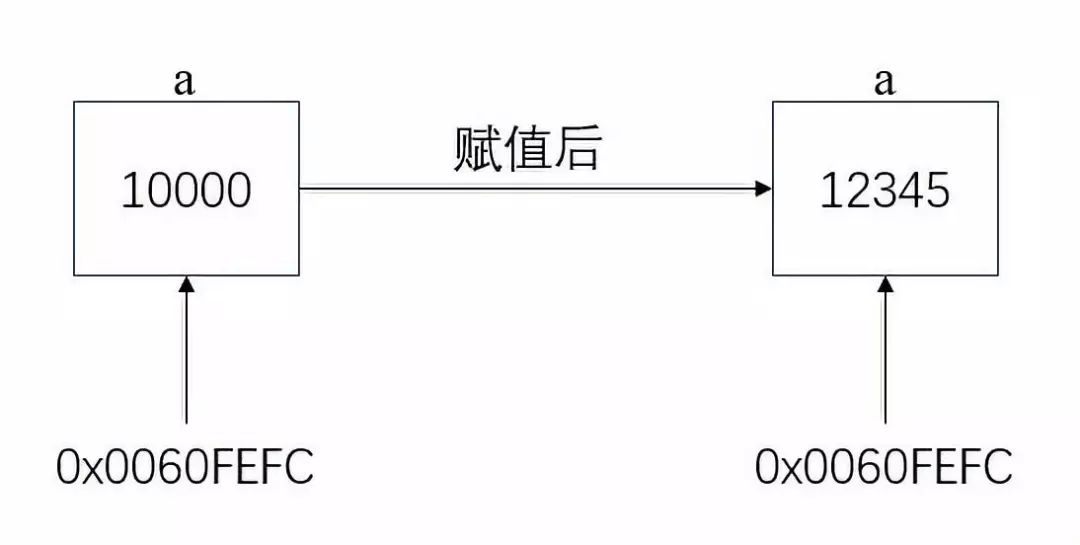
举例来说,对于如下的 C 代码:
int a = 10000;printf("original address: %pn", &a); // original address: 0060FEFCa = 12345;printf("second address: %pn", &a); // second address: 0060FEFC
对于有 C 语言编程经验的人来说,上述结果是显而易见的:变量a的地址并不会因为赋给它的值有变化而发生变化。对于 C 编译器来说,变量a只是协助它区别各个内存地址的标识,是直接与特定的内存地址绑定的,如图所示:
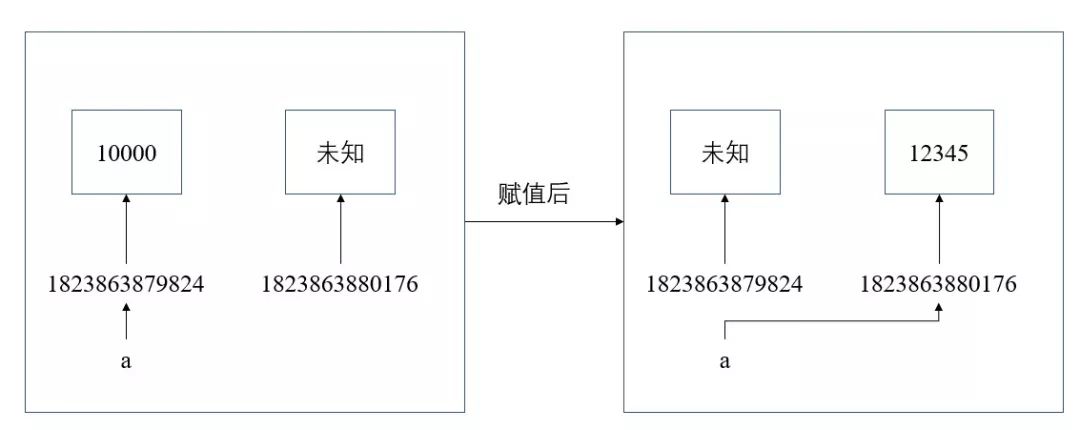
 但 Python 就不一样的。考虑如下代码:
但 Python 就不一样的。考虑如下代码:>>> a = 10000>>> id(a)1823863879824>>> a = 12345>>> id(a)1823863880176
这就有点儿意思了,更加神奇的是,即使赋给变量同一个常数,其得到的id也可能不同:
>>> a = 10000>>> id(a)1823863880304>>> a = 10000>>> id(a)1823863879408
假如a对应的数据类型是一个列表,那么:
>>> a = [1,2]>>> id(a)2161457994952>>> a = [1,2]>>> id(a)2161458037448
得到的id值也是不同的。
正如前文所述,在 Python 中,变量就是一块砖,哪里需要哪里搬。每次将一个新的对象赋值给一个变量,都在内存中重新创建了一个对象,这个对象就具有新的引用值。作为一个“标签”,变量也是哪里需要哪里贴,毫无节操可言。
但要注意的是,这里还有一个问题:之所以说“即使赋给变量同一个常数,其得到的
id也可能不同”,实际上是因为并不是对所有的常数都存在这种情况。以常数1为例,就有如下结果:
>>> a = 1>>> id(a)140734357607232>>> a = 1>>> id(a)140734357607232>>> id(1)140734357607232可以看到,常数
1对应的id一直都是相同的,没有发生变化,因此变量a的id也就没有变化。这是因为Python在内存中维护了一个特定数量的常量池,对于一定范围内的数值均不再创建新的对象,而直接在这个常量池中进行分配。实际上在我的机器上使用如下代码可以得到这个常量池的范围是 [0, 256] ,而 256 刚好是一个字节的二进制码可以表示的值的个数。
for b in range(300):if b is not range(300)[b]:print("常量池最大值为:", (b - 1))break# 常量池最大值为:256
相应地,对于数值进行加减乘除并将结果赋给原来的变量,都会改变变量对应的引用值:
>>> a = 10000>>> id(a)2161457772304>>> a = a + 1>>> a10001>>> id(a)2161457772880
比较代码块第 3、8行的输出结果,可以看到对数值型变量执行加法并赋值会改变对应变量的引用值。这样的表现应该比较好理解。因为按照 Python 运算符的优先级,a = a + 1实际上就是a = (a + 1),对变量a对应的数值加1之后得到的是一个新的数值,再将这个新的数值赋给a ,于是a的引用也就随之改变。列表也一样:
>>> a = [1,2]>>> id(a)2161458326920>>> a = a + [4]>>> a[1, 2, 4]>>> id(a)2161458342792
2.2 不变的情况
与数值不同,Python 中对列表对象的操作还表现出另一种特性。考虑下面的代码:
>>> c = [1, 2, 3]>>> id(c)2161458355400>>> c[2] = 5>>> c[1, 2, 5]>>> id(c)2161458355400>>> c.append(3)>>> c[1, 2, 5, 3]>>> id(c)2161458355400
观察代码块第 3、8、13三行,输出相同。也就是说,对于列表而言,可以通过直接操作变量本身,从而在不改变其引用的情况下改变所引用的值。
更进一步地,如果是两个变量同时引用同一个列表,则对其中一个变量本身直接进行操作,也会影响到另一个变量的值:
>>> c = [1, 2, 3]>>> cc = c>>> id(c)1823864610120>>> id(cc)1823864610120
显然此时的变量c和cc的id是一致的。现在改变c所引用的列表值:
>>> c[2] = 5>>> cc[1, 2, 5]
可以看到cc所引用的列表值也随之变化了。再看看相应地id:
>>> id(c)1823864610120>>> id(cc)1823864610120
两个变量的id都没有发生变化。再调用append()方法:
>>> c.append(3)>>> c[1, 2, 5, 3]>>> cc[1, 2, 5, 3]>>> id(c)1823864610120>>> id(cc)1823864610120
删除元素:
>>> del c[3]>>> c[1, 2, 5]>>> cc[1, 2, 5]>>> id(c)1823864610120>>> id(cc)1823864610120
在上述所有对列表的操作中,均没有改变相应元素的引用。
也就是说,对于变量本身进行的操作并不会创建新的对象,而是会直接改变原有对象的值。
2.3 一个特殊的地方
本小节示例灵感来自[关于Python中的引用[7]]
数值数据和列表还存在一个特殊的差异。考虑如下代码:
>>> num = 10000>>> id(num)2161457772336>>> num += 1>>> id(num)2161457774512
有了前面的铺垫,这样的结果很显得很自然。显然在对变量num进行增1操作的时候,还是计算出新值然后进行赋值操作,因此引用发生了变化。
但列表却不然。见如下代码:
>>> li = [1, 2, 3]>>> id(li)2161458469960>>> li += [4]>>> id(li)2161458469960>>> li[1, 2, 3, 4]
注意第 4 行。明明进行的是“相加再赋值”操作,为什么有了跟前面不一样的结果呢?检查变量li的值,发现变量的值也确实发生了改变,但引用却没有变。
实际上这是因为加法运算符在 Python 中存在重载的情况,对列表对象和数值对象来说,加法运算的底层实现是完全不同的,在简单的加法中,列表的运算还是创建了一个新的列表对象;但在简写的加法运算+=实现中,则并没有创建新的列表对象。这一点要十分注意。
3. 原理解析
前面(第3天:Python 变量与数据类型[8])我们提到过,Python 中的六个标准数据类型实际上分为两大类:可变数据和不可变数据。其中,列表、字典和集合均为“可变对象”;而数字、字符串和元组均为“不可变对象”。实际上上面演示的数值数据(即数字)和列表之间的差异正是这两种不同的数据类型导致的。
由于数字是不可变对象,我们不能够对数值本身进行任何可以改变数据值的操作。因此在 Python 中,每出现一个数值都意味着需要另外分配一个新的内存空间(常量池中的数值例外)。
>>> a = 10000>>> a == 10000True>>> a is 10000False>>> id(a)2161457773424>>> id(10000)2161457773136>>>from sys import getrefcount>>> getrefcount(a)2>>> getrefcount(10000)3
前 9 行的代码容易理解:即使是同样的数值,也可能具有不同的引用值。关键在于这个值是否来自于同一个对象。
而第 10 行的代码则说明除了getrefcount()函数的引用外,变量a所引用的对象就只有1个引用,也就是变量a。一旦变量a被释放,则相应的对象引用计数归零,也会被释放;并且只有此时,这个对象对应的内存空间才是真正的“被释放”。
而作为可变对象,列表的值是可以在不新建对象的情况下进行改变的,因此对列表对象本身直接进行操作,是可以达到“改变变量值而不改变引用”的目的的。
4. 总结
对于列表、字典和集合这些“可变对象”,通过对变量所引用对象本身进行操作,可以只改变变量的值而不改变变量的引用;但对于数字、字符串和元组这些“不可变对象”,由于对象本身是不能够进行变值操作的,因此要想改变相应变量的值,就必须要新建对象,再把新建对象赋值给变量。
通过这样的探究,也能更加生动地理解“万物皆对象”的深刻含义。
5. 参考资料
Python 3.7.4 文档-内置函数-id()[9]
Python 3.7.4 文档-内置类型[10]
Python 3.7.4 文档-sys模块——系统相关参数及函数[11]
Python 3.7.4 文档-术语表[12]
-
第16天:Python 错误和异常
-
第15天:Python 输入输出
-
第 14 天:Python 高阶函数
-
第13天:Python 函数的参数
-
第12天:Python 集合
-
第11天:Python 字典
-
第10天:Python 类与对象
-
第9天: Python tupple
-
第8天:Python List
-
第7天:Python 数据结构–序列
-
第6天:Python 模块和
-
第5天:Python 函数
-
第4天:Python 流程控制
-
第3天:Python 变量与数据类型
-
第2天:Python 基础语法
-
第1天:Python 环境搭建
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏





