【你只会用ChatGPT聊天?】我已用它做爬虫、抓数据、自动导出csv!挣钱中,勿扰!
【你只会用ChatGPT聊天?】我已用它做爬虫、抓数据、自动导出csv!挣钱中,勿扰!
在本文中,我们将介绍如何使用ChatGPT来编写Python代码,实现网站数据的自动抓取和导出到CSV文件的功能。
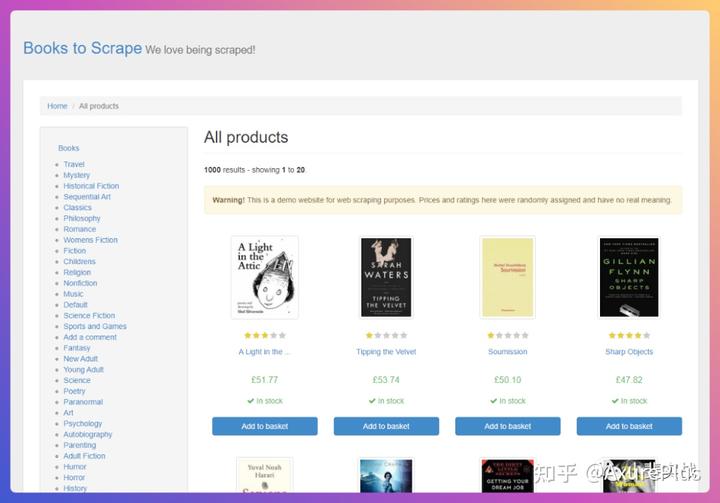
目标网站
今天这个案例,我们以一个图书网站作为目标网站,使用ChatGPT来一步步完成编写代码、抓取数据、自动导出的功能。
实现步骤
首先我们在ChatGPT的输入框里输入以下内容,让chatgpt使用python和beautifulsoup来抓取目标网站的数据。
web scrape https://books.toscrape.com/ using python and beautifulsoup这里需要介绍一下beautifulsoup,因为对于大家来说python应该耳熟能详,但是beautifulsoup可能大家会有点儿陌生。
BeautifulSoup介绍
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.BeautifulSoup会帮你节省数小时甚至数天的工作时间。
我们回到ChatGPT的界面,可以看到它已经帮我们生成好了代码,内容如下:
import requests
from bs4 import BeautifulSoup
url = "https://books.toscrape.com/"
# Send a GET request to the website
response = requests.get(url)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Find all the book titles and prices on the first page
for book in soup.find_all("article", class_="product_pod"):
title = book.h3.a["title"]
price = book.select(".price_color")[0].get_text()
print(title, price)可以看到在代码开头需要导入request和BeautifulSoup的库,所以如果你没有安装的话,允许py代码会报错的,你可以通过下面的命令进行安装。
pip install requests
pip install beautifulsoup42个库安装完成后,我们将上面的代码,拷贝到test.py文件中,在cmd命令行模式输入以下命令允许这个python文件:
python test.py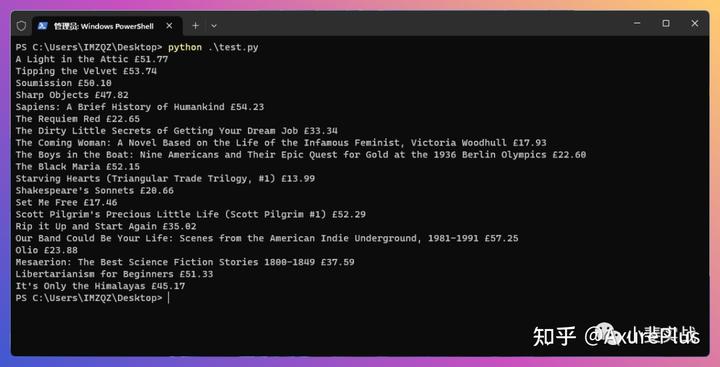
正常执行后,可以看到返回的数据了,包括“书名”和“价格”,以第一条内容为例:A Light in the Attic £51.77,其中A Light in the Attic是书名,£51.77是价格。
这里只抓取了页面中的标题和价格2个字段,如果我们还想获取每本书的页面链接怎么做?当然让ChatGPT继续干活了,在窗口继续输入以下内容:
also scrape link to each book接着ChatGPT又开始埋头写代码了,最终生成代码如下:
import requests
from bs4 import BeautifulSoup
url = "https://books.toscrape.com/"
# Send a GET request to the website
response = requests.get(url)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Find all the book titles, prices, and links on the first page
for book in soup.find_all("article", class_="product_pod"):
title = book.h3.a["title"]
price = book.select(".price_color")[0].get_text()
link = book.h3.a["href"]
book_url = url + link.replace("../../", "")
print(title,'/', price, '/', book_url)可以看到这段代码中多了下面的2行
link = book.h3.a["href"]
book_url = url + link.replace("../../", "")我们继续保存代码,重新执行看看结果
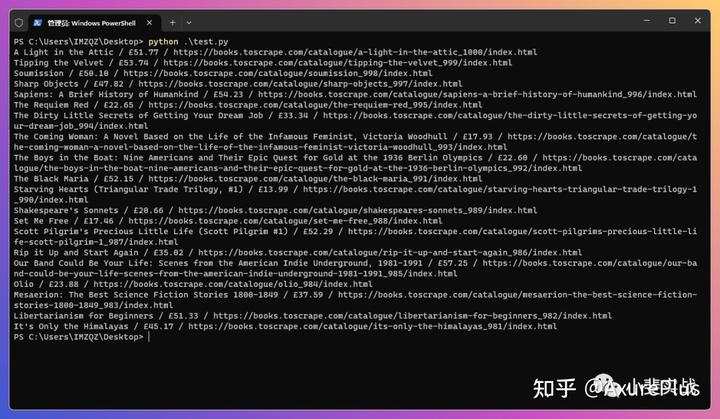
这次输出的内容中使用/将3个字段进行了区分,标题/价格/链接,看起来还不错,有了这些数据基础,我们下一步来尝试将生成的内容,自动导出为csv文件。
继续在ChatGPT的窗口输入以下内容:
export data to csv fileChatGPT埋头撸代码中,最后输出结果如下:
import csv
import requests
from bs4 import BeautifulSoup
url = "https://books.toscrape.com/"
# Send a GET request to the website
response = requests.get(url)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Create a CSV file and write the headers
with open("book_data.csv", "w", newline="") as file:
writer = csv.writer(file)
writer.writerow(["Title", "Price", "URL"])
# Find all the book titles, prices, and links on the first page
for book in soup.find_all("article", class_="product_pod"):
title = book.h3.a["title"]
price = book.select(".price_color")[0].get_text()
link = book.h3.a["href"]
book_url = url + link.replace("../../", "")
writer.writerow([title, price, book_url])这段新生成的代码,多出了创建csv文件的内容:
# Create a CSV file and write the headers
with open("book_data.csv", "w", newline="") as file:
writer = csv.writer(file)
writer.writerow(["Title", "Price", "URL"])保存运行,你会发现,运行报错,意思就是GBK不行,那怎么办?
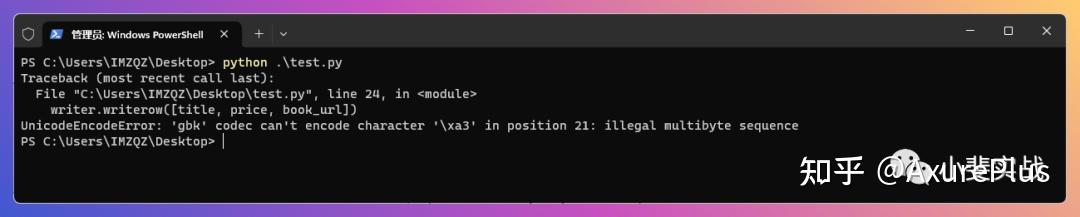
那只能再劳烦ChatGPT了,输入以下内容:
use utf8 encoder让它使用utf8的编码进行导出csv,得到以下代码
import csv
import requests
from bs4 import BeautifulSoup
url = "https://books.toscrape.com/"
# Send a GET request to the website
response = requests.get(url)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Create a CSV file and write the headers
with open("book_data.csv", "w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["Title", "Price", "URL"])
# Find all the book titles, prices, and links on the first page
for book in soup.find_all("article", class_="product_pod"):
title = book.h3.a["title"]
price = book.select(".price_color")[0].get_text()
link = book.h3.a["href"]
book_url = url + link.replace("../../", "")
writer.writerow([title, price, book_url])可以看到,代码中加入了对编码格式的要求
with open("book_data.csv", "w", newline="", encoding="utf-8") as file:运行看看结果,这次就很完美了,没有任何报错和反馈,这代表文件已经生成完毕。

快!快!快!打开CSV文件看看效果。3个字:帅呆了!
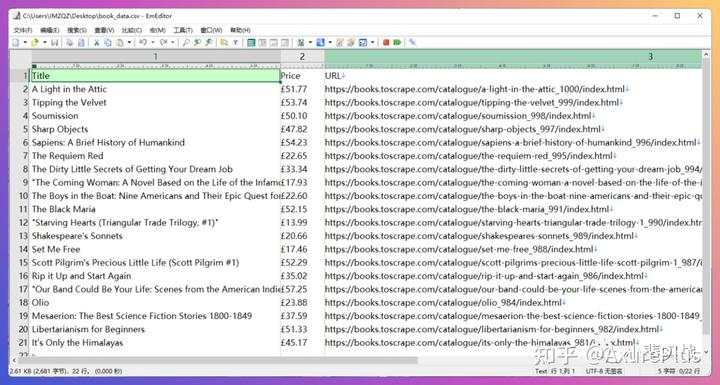
使用ChatGPT编写Python代码,可以极大地简化和优化爬虫程序的编写过程,实现自动抓取网站数据和导出CSV文件的功能。
我们在本文中介绍了使用ChatGPT编写爬虫程序的基本步骤,并提供了一些实用的代码示例。同时,我们还要强调在进行网络数据抓取时需要遵守相关法律法规,尊重网站所有者的权益,避免对网站造成不必要的麻烦。
希望本文能够对您学习和掌握Python编程和网络爬虫技术有所帮助,同时也能够在使用ChatGPT进行自然语言生成方面提供一些启示。
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏




