python浏览器复制粘贴到word里(带格式的)
写这篇文章的目的是我在网上找了许多方法,各种各样的方法都用了个遍,包括使用UiPath我都没有找到合适的方法。接来下写我的解决过程。
需求:
http://stats.gd.gov.cn/gmjjzyzb/content/post_3900512.html
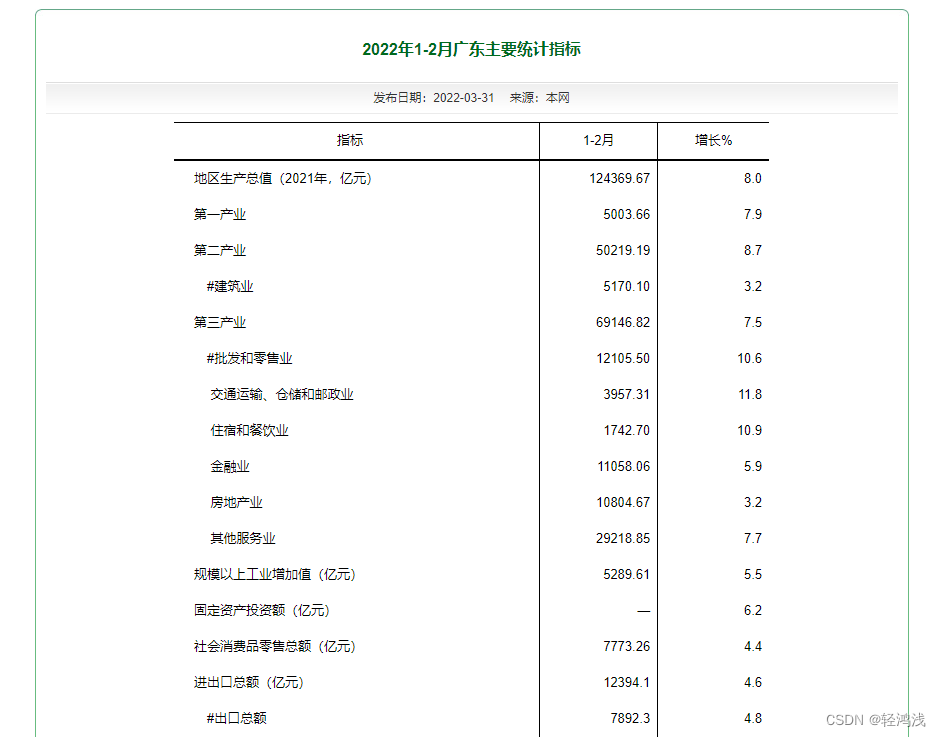
以该网页为例,客户需要将该网页的表格按照该网页的格式复制到word中。注意是要求格式一致。
需求:
http://stats.gd.gov.cn/gmjjzyzb/content/post_3900512.html
以该网页为例,客户需要将该网页的表格按照该网页的格式复制到word中。注意是要求格式一致。
我做了如下几种尝试:
1、使用selenium中的ActionChains方法,其中有鼠标拖拽的方法,但是并没有成功,该方法只能使用在可操作的空间。
2、使用保存.html格式的文件,然后使用pypandoc的方法进行html和docx之间的转换:
# -*- coding:utf-8 -*-
import pypandoc
# html文档的位置
html_path = r"C:\Users\tianyi.zhang\Desktop\广东省统计局-2022年1-2月广东主要统计指标.html"
# 转换生成word文档的位置
word_path = r"C:\Users\tianyi.zhang\Desktop\广东省统计局-2022年1-2月广东主要统计指标.docx"
pypandoc.convert_file(html_path, 'docx', outputfile=word_path)
但是出来的只有表格的样子,并没有那个表格的边框,以及会出现很多没用的数据
3、最后解决还是用的ActionCains方法,算是一个比较取巧的方法
from selenium import webdriver
from time import sleep
import autoit as au
from win32com.client import Dispatch
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
import warnings
warnings.filterwarnings("ignore")
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("http://stats.gd.gov.cn/gmjjzyzb/content/post_3900512.html")
sleep(2)
start = driver.find_element_by_xpath("//h2[text()='国民经济主要指标']")
end = driver.find_element_by_xpath("//div[@class='bshare-custom icon-medium']")
ActionChains(driver).click(start).key_down(Keys.SHIFT).click(end).key_up(Keys.SHIFT).perform()
sleep(2)
au.send('^c')
sleep(1)
app =Dispatch('Word.Application')
# 新建word文档
doc = app.Documents.Open(r"C:\Users\tianyi.zhang\Desktop\test.docx")
app.Visible = 1
sleep(1)
au.send('^v')
sleep(1)
au.send('^s')
sleep(1)
doc.Close()
我在这里说明一下为什么不提取出来html中的text数据然后存入到docx中然后调整样式。首先正式的客户场景我不仅仅一个这样的表格,还有很多表格存在合并,居中,拆分的格式,没办法将样式统一。其次如果以后还有更多的需求,比如说一段文字后添加一个表格,然后还要添加图片等,这些都是没办法用selenium和docx实现一个统一的样式的。
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏

