Python爬虫之正则表达式
正则表达式
正则表达式就是规则表达式,在接触爬虫前,正则表达式就是用来过滤的。接触爬虫后发现真的就是过滤用的hhh。正则表达式在爬虫中的作用就是过滤出想要的字符,然后获取,如果不用正则表达式,那么就会将网页中大量信息全部爬出,造成大量内存浪费,亦不是我们最初想要爬取某些东西的初衷。
正则表达式原理
通过正则表达式我们可以实现
- 给定的字符串是否符合正则表达式的过滤逻辑(匹配
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(过滤
语法介绍
正则表达式室友普通字符(a-z)以及特殊字符(“元字符”)组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。
真个则表达式的组件可以是单个字符、字符合集、字符范围、字符间的选择或者所有这些组件的任意组合。正则表达式中的字符一般分为普通字符、非打印字符、特殊字符、限定符、定位符等。
普通字符
正常能够被打印的字符
包括没有显示指定为元字符的所有可打印何不可打印字符。这包括所有大写和小写字母,所有数字,所有标点符号和一些其他符号。
正则表达式在线测试:在线正则表达式测试
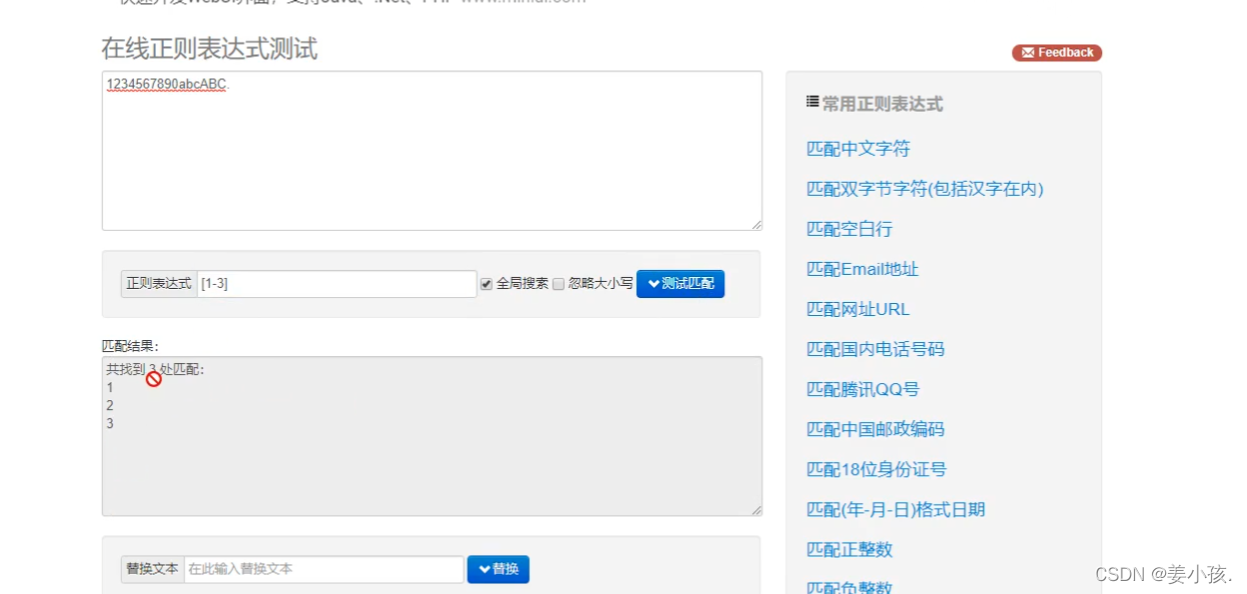
注意字符串集合和字符串的区别(图一是集合,图二是字符串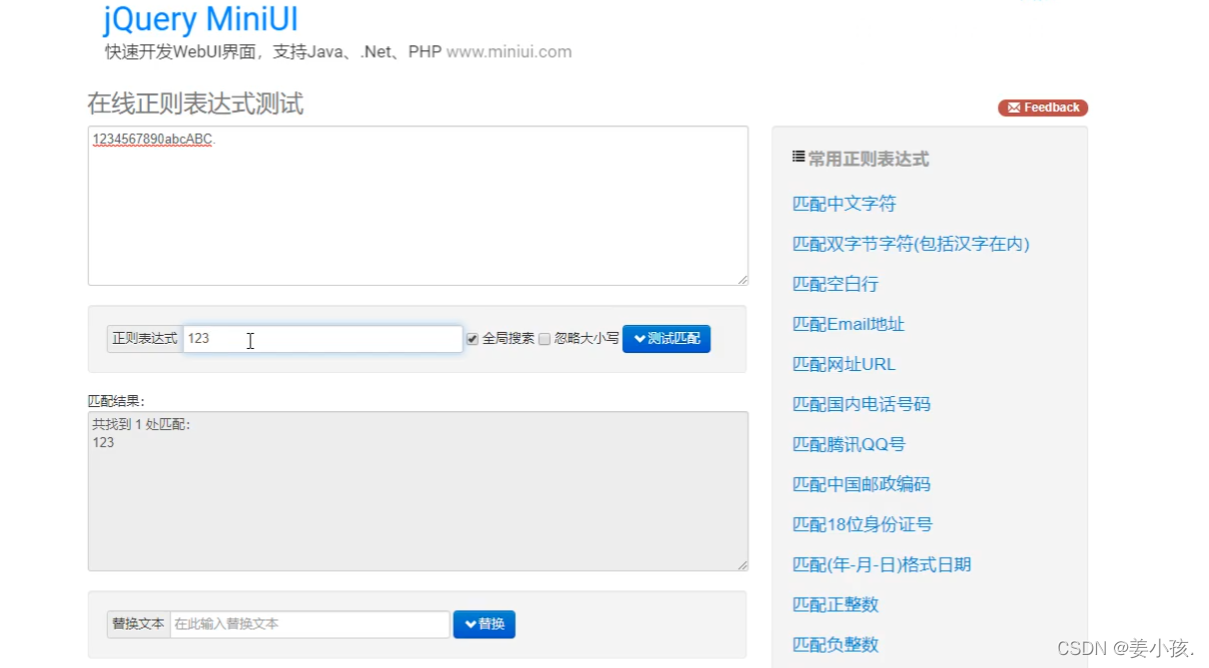
非打印字符
非打印字符是打印出来,但实际看不到
| \cx | 匹配由x指明的控制字符,如\cM匹配一个Control-M1或者回车符。X值必须为A-Z或a-z之一。否则c将是一个原意的’c’字符。 |
|---|---|
| \f | 匹配一个换页符,等价\x0c和\cI。 |
| \n | 匹配一个换行符,等价\x0d和\cJ。 |
| \r | 匹配一个回车符,等价\x0d和\cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[\f\v\r\t\v] |
| \S | 匹配任何非空白字符。等价于\f\v\r\t\v |
| \t | 匹配一个制表符,等价\x09个\cI |
| \v | 匹配垂直制表符,等价\x0b和\cK |
特殊字符
有特殊含义的字符。如果要匹配这些元素需要在字符前面加转义符,即反斜杠字符[]。
| $ | 匹配输入字符串结尾位置(有几行 |
|---|---|
| [] | 标记一个子表达式的开始和结束位置,子表达式可以获取供后面使用 |
| * | 匹配前面的子表达式0次或多次 |
| + | 匹配前面的子表达式1次或多次 |
| . | 匹配除换行符\n之外的任何单个字符 |
| [ | 标记一个中括号表达式的开始 |
| ? | 匹配前面的子表达式0次或1次,或指明一个非贪婪限定符。 |
| \ | 讲下一个字符标记为或特殊字符、或原意字符、或向后引用、或八进制转义符。 |
| ^ | 匹配输入字符串的开始位置、除非在方括号表达式中使用,此时它表示排除该字符的集合 |
| { | 标记限定符表达式的开始。 |
| | | 指明两项之间的一个选择 |
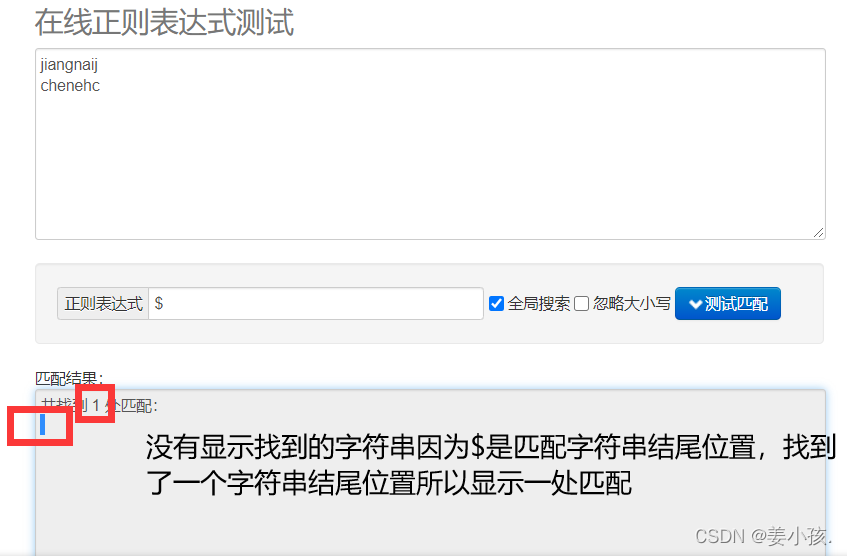
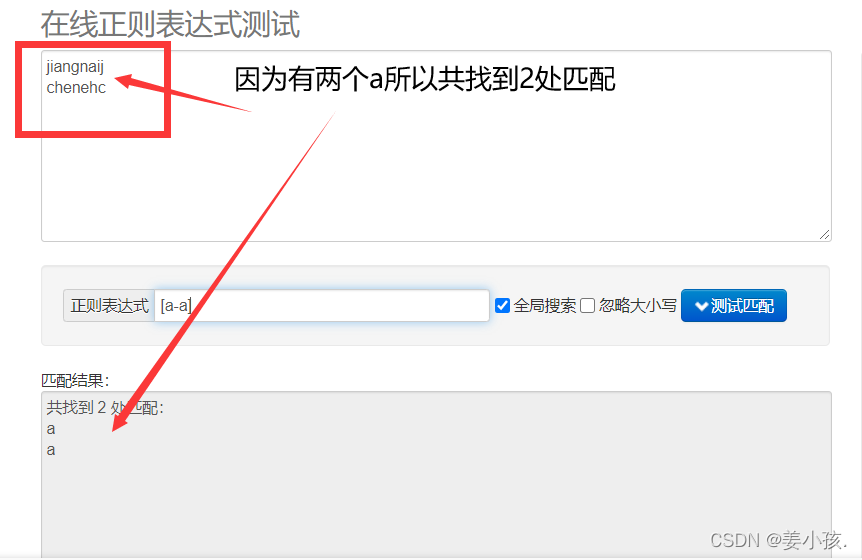
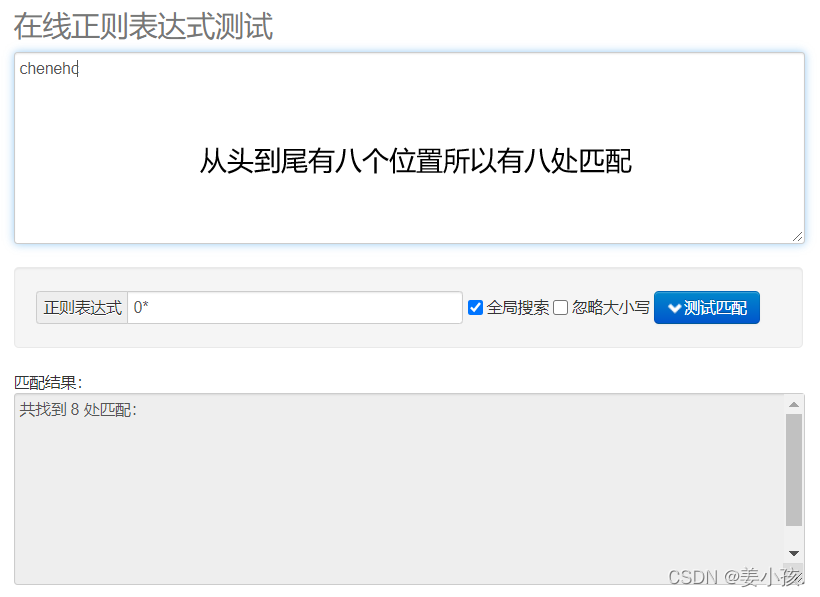
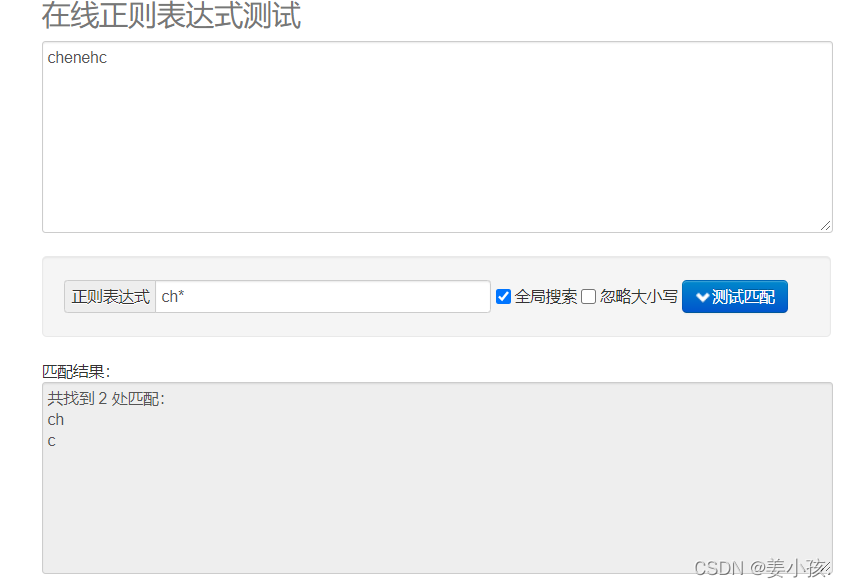
和+的用法要比较来看,+比的要求更加严格 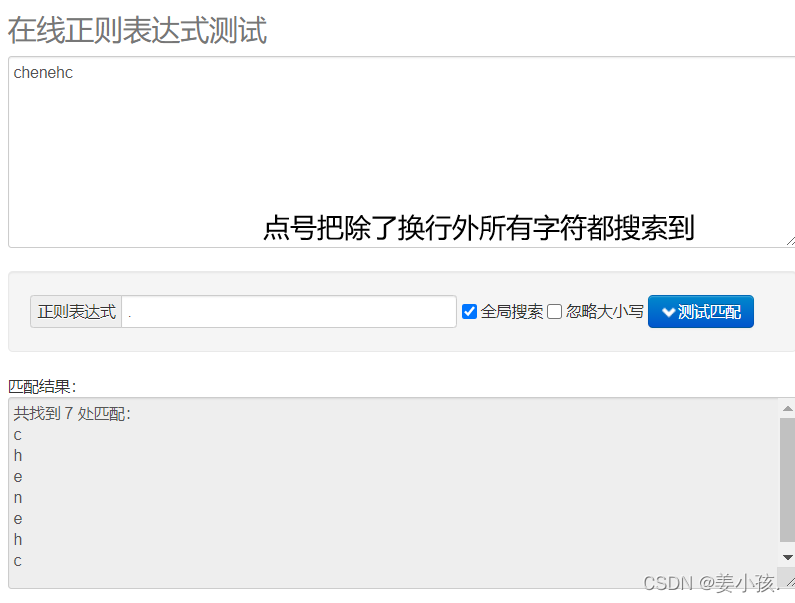
?用法和Windows中文件搜索的?一样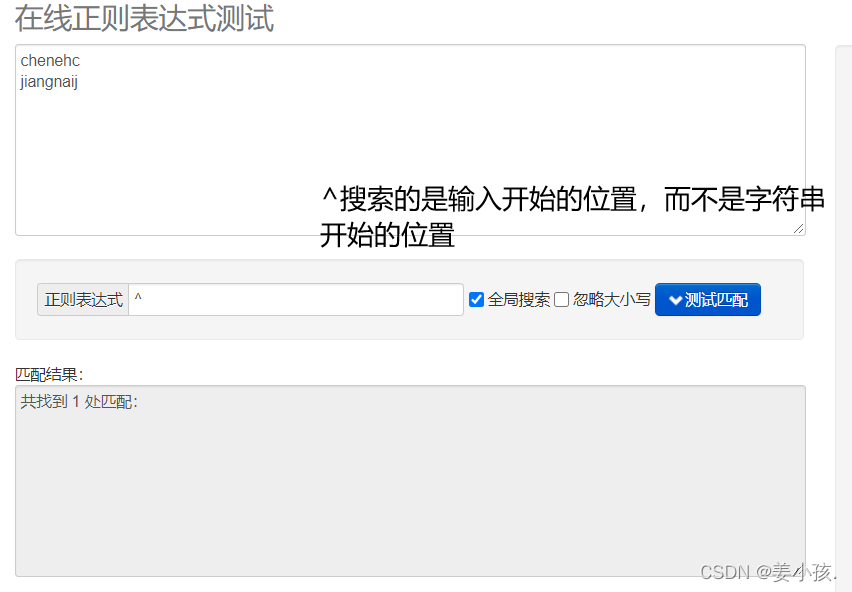
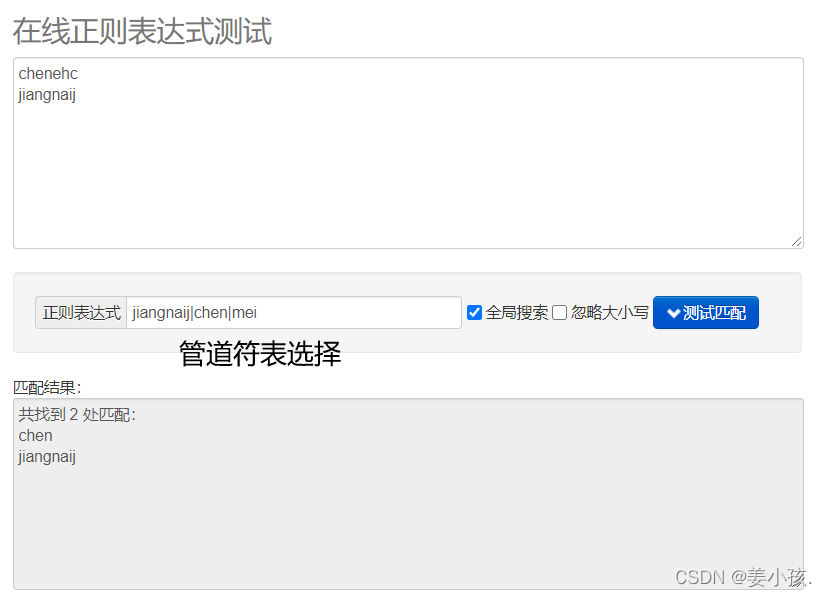
管道符可以实现同时匹配,可以理解为或
限定符
| * | 匹配前面的子表达式0次或多次。例如,zo能匹配”z”以及”zoo”,等价于{0,} |
|---|---|
| + | 匹配前面的子表达式1次或多次,例如,’zo+’能匹配”zo”以及”zoo”,但不能匹配”z”。+等价于{1,} |
| ? | 匹配前面的子表达式0次或1次.例如”do[es]?”可以匹配”do”或”does”中的do。?等价于{0,1} |
| {n} | n是一个非负整数,匹配确定的n次。例如,’o{2}’不能匹配”BOb”中的o,但能匹配’fooooood’中所有的o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如’0{2,}’不能匹配”BOb”中的’o’,但能匹配”foooooood”中所有的o。’0{1,}’等价于’0+’。’o{0,}’则等价于”o” |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且做多匹配m次。例如,”o{1,3}”将匹配”foooooood”中的前三个o。’o{0,1}’等价于’0?’。注意在逗号和两个数之间不能有空格 |
常用函数
- re.findall[] 最常用
- re.conpile[]
- re.match[] 最常用
- re.search[] 最常用
- re.finditer[]
- re.sub[] 最常用
- re.subn[]
- re.split[]
re.findall[]函数
语法:re.findall[pattern,string,flags=0]–>list[列表]
列出字符串模式中的u送头匹配项,并作为列表储存在list列表中
与re.search[]不一样的地方:
re.findall返回的是列表
re.search返回的是文本
re.findall返回的是列表,re.search返回文本
re.findall匹配多个值,re.search只要匹配到就返回,只匹配一个值
re.compile[]函数
语法:re.compile[pattern,flags=0]—>pattern object
根据包含正则表达式的字符串创建模式对象,可以实现更有效率的匹配!用了re.compile以后,正则对象会得到保留,这样在需要多次运用这个正则对象的时候效率会有较大的提升
此外,re.compile[]可以接受可选属性,常用来实现不同的特殊功能和语法变更。
MatchObject(匹配对象)方法
group[]:返回被正则匹配的字符串;
start[]:返回匹配开始的位置;
end[]:返回匹配结束的位置;
span[]:返回一个元组包含匹配(开始,结束)的位置。
re.match[]函数
语法:re.match[pattern,string,flags=0]—–>match object or None
在字符串的开始位置匹配正则!如果无匹配,返回None
re.search[]函数
语法:re.search[pattern,string,flags=0]—–>match object or None
re.search 函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None
re.match与re.search的区别:re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失效,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
re.finditer[]函数
语法:re.finditer[pattern,string,flags=0]—–>iterator
列出字符串中模式的所有匹配项,并作为一个迭代器(可以被for循环,可以被next遍历)返回。
re.sub[]函数
语法:re.sub[pattern,repl,string,sount=0,flags=0]———>string
将字符串中所有pattern的匹配项用repl替换
re.subn[]函数
语法:re.subn[pattern,repl,string,count=0,flags=0]
与sub[]实现相同的替换作用,但是subn[]返回一个元组,其中包含新字符串和替换次数!
re.split[]函数
语法:re.split[pattern,string,maxsplit=0,flags=0]—–>list
根据模式的匹配项来分割字符串!
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏



