python爬虫爬取一章节小说
一、爬虫技术简介
1.1什么是网络爬虫?
(1)官方定义:网络爬虫又称为网页蜘蛛(web spider)是按照一定的规则自动抓取万维网信息的程序或脚本。它模仿浏览器访问网络资源,从而获取用户需要的信息,它可以为搜索引擎从万维网上下载网页信息,因此也是搜索引擎的重要组成部分。
(2)定义一:网络爬虫是一个自动提取网页的程序,它为搜索引擎从web上下载网页,是搜索引擎的重要组成部分。通用网络爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL列表;在抓取网页的过程中,不断从当前页面上抽取新的URL放入待爬行队列,直到满足系统的停止条件。
(3)定义二:逐题网络爬虫就是跟就一定的网页分析算法过滤与主题无关的链接,保留主题相关的链接并将其放入待抓取的URL队列中;然后根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统某一条件时停止。所有被网络爬虫抓取的网页将会被系统存储,进行一定的分析、过滤,并建立索引,对于主题网络爬虫来说,这一过程所得到的分析结果还可能对后续的抓取过程进行反馈和指导。
(4)定义三:如果网页P中包含超链接1,则P称为超链接1父网页。
(5)定义四:如果超链接1指向网页t,则网页t称为子网页,又称为目标网页。主题网络爬虫的基本思路就是按照事先给出的主题,分超链接和已经下载的网页内容,预测下一个待抓取的URL及当前网页的主题相关度,保证尽可能多地爬行、下载与主相关的网页,尽可能少地下载无关网页。
1.2网络爬虫的分类
对于网络爬虫来说,常见的有以下三类。
第一类是爬取页面、玩转网页的,这种类型的网络爬虫规模都比较小,数据量也比较小,爬取的速度不敏感,大多数使用Requests类库。
第二类是爬取网站、爬取系列网站的,这种类型的网络爬虫属于中等规 模,爬取的数据量也比较大,它对爬取速度敏感,使用Scrapy类库。
第三类是全网爬取,这种类型就属于大规模全Internet搜索引擎,爬取速度是它的关键,它们使用的类库都是定制开发的。
1.3 Python爬虫网络库
Python爬虫网络库主要包括:urllib、requests、grab、pycurl、urllib3、httplib2、RoboBrowser 、MechanicalSoup、mechanize、socket、Unirest for
Python、hyper、PySocks、treq以及aiohttp等。
1.4 Python爬虫框架
Python网络爬虫框架主要包括:grab、scrapy、pyspider、cola、portia、restkit以及demiurge等。
调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
应用程序:就是从网页中提取的有用数据组成的一个应用。
1.5 HTML/XML解析器
(1)lxml:C语言编写高效HTML/ XML处理库,支持XPath;
(2)cssselect:解析DOM树和CSS选择器;
(3)pyquery:解析DOM树和jQuery选择器;
(4)BeautifulSoup:低效HTML/ XML处理库,纯Python实现
(5)html5lib:根据WHATWG规范生成HTML/ XML文档的DOM,该规范被用在现
在所有的浏览器上;
(6)Feedparser:解析RSS/ATOM feeds
(7)MarkupSafe:为XML/HTML/XHTML提供了安全转义的字符串;
(8)Xmltodict:一个可以让你在处理XML时感觉像在处理JSON一样的Python模块;
(9)Xhtml2pdf:将HTML/CSS转换为Pdf
(10)Untangle:轻松实现将XML文件转换为Python对象
(11)Bleach:清理HTML(需要html5lib);
二、Python概述
Python语言是一种功能强大面向对象的解释型计算机程序设计语言,能有效而且简单地实现面向对象编程。Python语言属于语法简洁清晰的开源编程语言,特色之一是强制用空白符(white space)作为语句缩进。
Python具有丰富的标准库和强大的第三方库。它常被昵称为胶水语言,能够和其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起,易于扩展。常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后可以用更合适的语言改写其中有特别要求的部分,比如对于性能要求特别高的3D游戏中的图形渲染模块,完全可以用C/C++重写封装为Python可以调用扩展类库。
在使用之前,必须搭建好使用环境。到Python官网下载针对用户所使用的操作系统Python版本来安装,安装完成后需要设置环境变量便于启动Python。同时可选择一款合适的编辑工具来完成爬虫的编写。
目前Python的版本有2.X和3.X。两者主要在语法、编码、性能、模块上有些不同。
使用Python开发爬虫的优点:
(1) 语言简洁,使用方便。
(2) 提供功能强大的爬虫框架。
(3) 丰富的网络支持库及网页解析器。
本文的爬虫是在Python3.6环境下调试完成的。
三、设计背景
3.1课题的来源及意义
互联网是一个庞大的非结构化的数据库,将数据有效的检索并组织呈现出来有着巨大的应用前景。搜索引擎是用户在网上冲浪时经常使用的一种工具,毫无疑问,每个用户都可以通过搜索引擎得到自己所需要的网络资源。搜索引擎一词在互联网领域得到广泛的应用,但是每个地区对它又有着不同的理解。在一些欧美国家搜索引擎常常是基于因特网的,它们通过网络爬虫程序采集网页,并且索引网页的每个词语,也就是全文检索。而在一些亚洲国家,搜索引擎通常是基于网站目录的搜索服务。
总的来说,搜索引擎只是一种检索信息的工具。它的检索方式分为以下两种:
一种是目录型的方式,爬虫程序把网络的资源采集在一起,再根据资源类型的不同而分成不同的目录,然后继续一层层地进行分类,人们查询信息时就是按分类一层层进入的,最后得到自己所需求的信息。另一种是用户经常使用的关键字方式,搜索引擎根据用户输入的关键字检索用户所需资源的地址,然后把这些地址反馈给用户。
搜索引擎作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。
但是,这些通用性搜索引擎也存在着一定的局限性。不同的领域、不同的背景的用户往往具有不同的检索目的和需求,通用型搜索引擎所返回的结果包含大量用户不关心的网页。为了解决这个问题,一个灵活的爬虫有着无可替代的重要意义。
3.2国内外发展状况
对于网络爬虫的研究从上世纪九十年代就开始了,目前爬虫技术已经趋见成熟,网络爬虫是搜索引擎的重要组成部分。网络上比较著名的开源爬虫包括Nutch,Larbin,Heritrix.网络爬虫最重要的是网页搜索策略(广度优先和最佳度优先)和网页分析策略(基于网络拓扑的分析算法和基于网页内容的网页分析算法)
四、设计目的
(1)巩固和加深对Python基本知识的理解和掌握。
(2)培养进行网络规划、管理及配置的能力或加深对网络协议体系结构的理解或提高Python编程能力。
(3)提高进行技术汇总报告和撰写说明书的能力。
五、设计过程
5.1步骤
(1) 明确目标:确定抓取哪个网站的哪部分数据。本实例确定抓取起点中文网中悬疑小说怪物调查手册的第十二章旧神。
(2) 分析目标:确定抓取数据的策略。一是分析要抓取得目标页面的URL格式,用来限定要抓取的页面的范围;二是分析要抓取的数据的格式,在本实例中就是要分析每一个词条页面中标题和简介所在的标签的格式;三是分析页面的编码,在页面解析器中指定页面编码,才能正确解析。
(3) 编写代码:在解析器中会用到目标步骤所得到的的抓取策略的结果。
(4) 执行爬虫程序
5.2 开始使用爬虫程序
5.2.1 URL解析器:
管理将要抓取的URL
5.2.2 Html下载器
Requests;bs4
(1)File–>settings或(Ctrl+Alt+S)进入settings界面
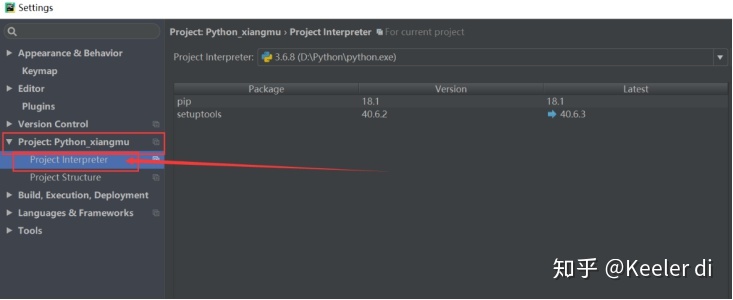
(2)进入Project Interpreter界面
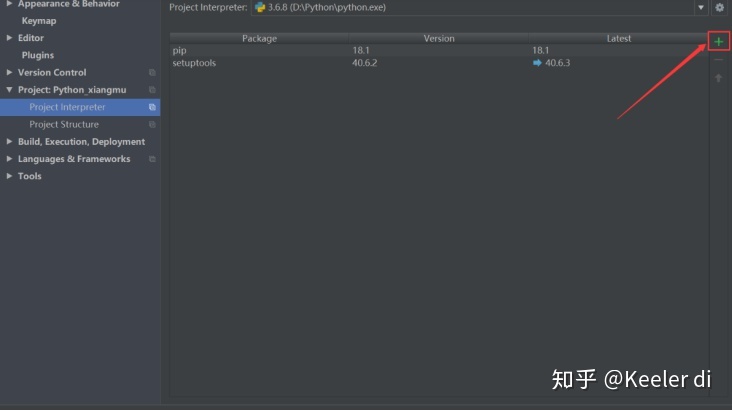
(3)安装bs4
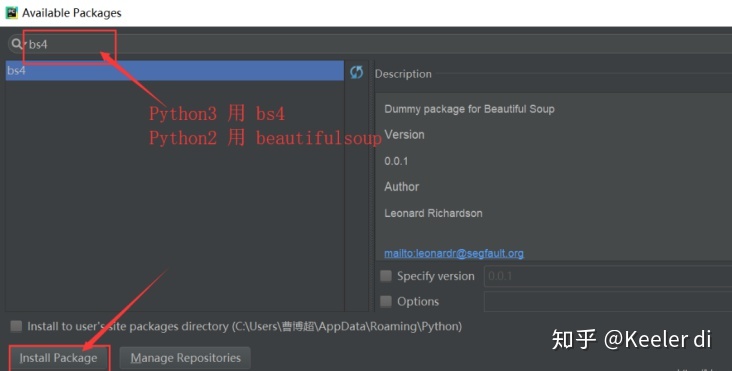
等待显示导入结果即可。requests的导入步骤与bs4的几乎一样。
5.2.3 编写程序
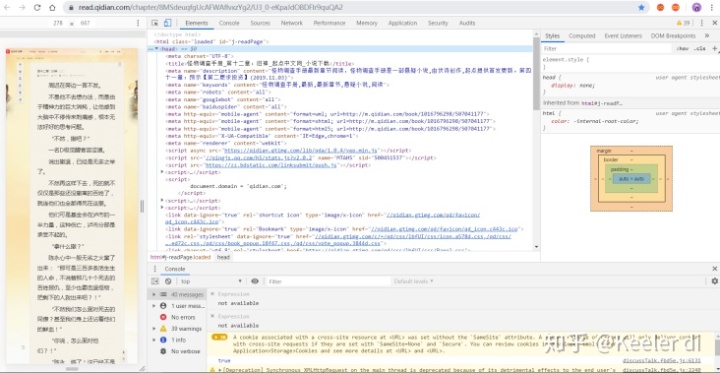
(1)找到爬取目标第十二章,并使用开发者工具打开如下图所示的页面:
(2)解析器
网页解析器:是从网页提取有价值的数据将网页下载器获取的Html字符串解析出有价值数据和新的url,使用最多的解析器有BeautifulSoup
(3)输出器
六、设计内容
以下为抓取小说文本内容的爬虫实例:
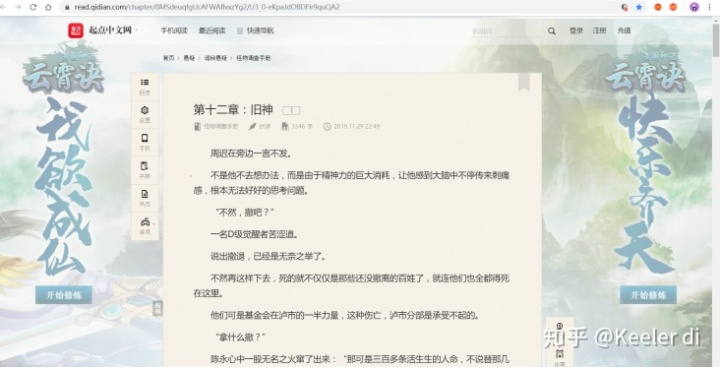
①我们先看一下第十二章小说的URL
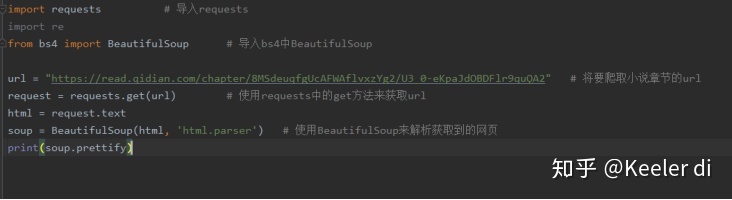
②我们先用已经学到的知识获取HTML信息,编写代码如下:
其运行结果如图所示:
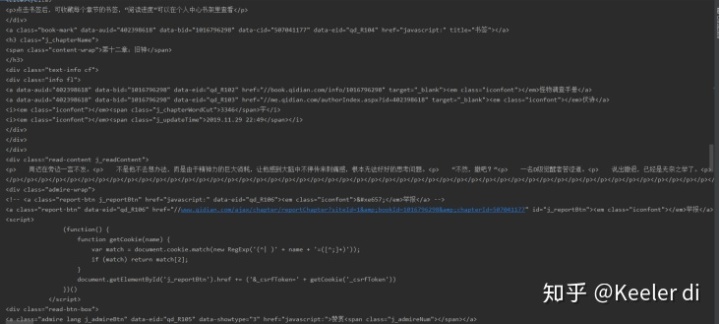
可以看到,我们很轻松地获取了HTML信息。但是,很显然,很多信息是我们不想看到的,我们只想获得正文内容,我们不关心div、br、这些html标签。如何把这些正文内容从这些众多的html 标签中提取出来呢?这是本次实战的主要内容。
Beautiful Soup
爬虫的第一步,获取整个网页的HTML信息,我们已经完成。接下来就是爬虫的第二步,解析HTML信息,提取我们感兴趣的内容。对于本例的实战,我们感兴趣的内容是文章的正文。提取的方法有很多,例如使用正则表达式、Xpath、Beautiful Soup等。对于初学者容易理解,并IQ而使用简单的方法是使用Beautiful Soup提取感兴趣的内容。
Beautiful Soup的安装方法和requests一样,使用如下指令安装(二选一)
Pip install beautifulsoup4
Easy_install beautifulsoup4
一个强大的第三方库,都会有一个详细的官方文档,Beautiful Soup 也是有中文的官方文档。URL:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
现在我们已经掌握审查元素的方法,查看一下我们的目标页面
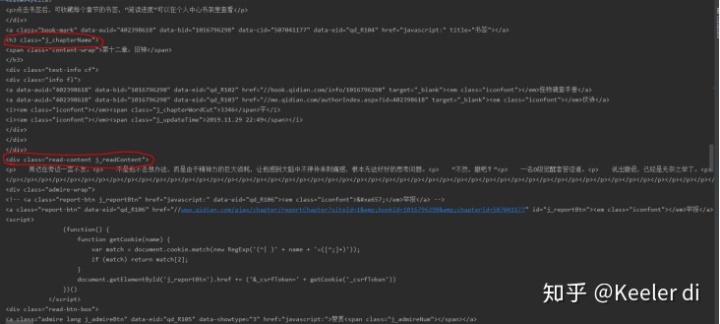
不难发现,文章的标题放在一个名为
的标签内,文章内容放在一个名为
的标签内。这个东西就是HTML标签,Html标签是html最重要的组成部分。
html标签就像一个个“口袋”,每个“口袋”都有自己的特定功能,负责存放不同的内容。显然,上图所示的div标签下存放了我们关系的正文内容。
细心的朋友可能已经发现,除了div字样以外,还有id和class就是div标签的属性,”read-content j_readContent”就是属性值。
仔细观察一番,我们会发现一个事实:class属性为”read-content j_readContent”的div标签,仅此一份。这个标签里存放的内容正是我们关心的正文部分。
知道这个信息后,我们就可以使用Beautiful Soup 提取我们想要的内容了,这里我们用到Beautiful Soup提供给我们的find()方法。
将其写入代码中:
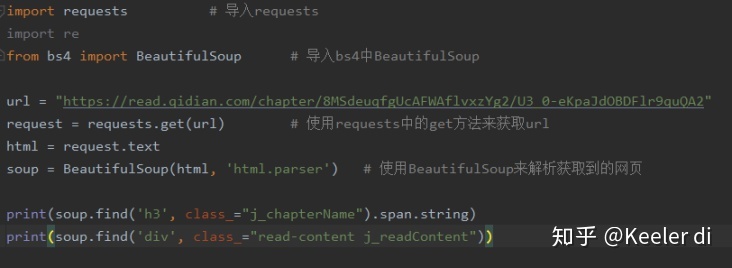
其运行结果如图所示:

我们可以看到,已经顺利匹配到我们关心的正文内容,但是还有一些我们不想要的东西,比如div标签名,
标签,以及空格。怎么去除这些东西呢?我们使用Beautiful Soup提供给我们的.string方法。
我们继续编写代码:

运行结果如下:
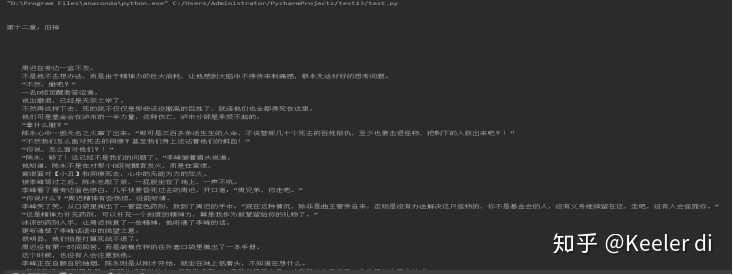
此时,我们已经得到了我们想要的最终结果。
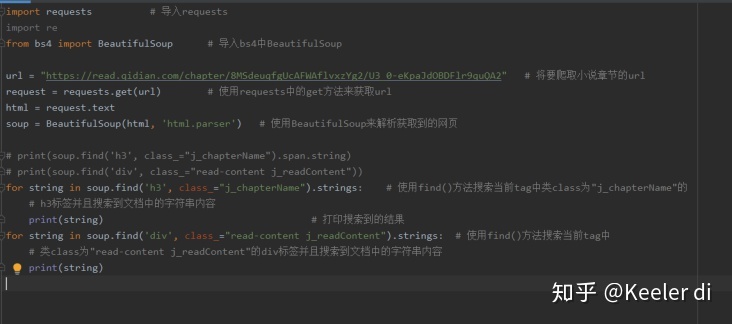
本例所有代码整合如下:
七、设计心得
一、工欲善其事必先利其器
想要爬取网站上的信息,必须有一个好的工具。firefox和chrome都有不错的工具,用chrome比较多,主要讲一下它的使用。《神器——Chrome开发者工具(一)》以及《chrome Dev tools》。我在这儿介绍一些高频使用的的功能。
1. F12:快捷键,(更多工具——开发者工具)。可以直接查看当前页面的html结构。有一点要注意,当前页面的html结构可能是Js动态生成的。比如淘宝网页的Josn数据源,但在开发者工具下是HTML结构。这个时候使用鼠标右键——查看源代码,可以看到json数据。
2.element选择键,F12后,下图中标示的方框内选项可以直接在页面中检索到对应的HTML标签位置——即在页面中点击选取。
3.console控制台,在这里可以看到一些与服务器的交互信息,上图中蓝色所指为清空,在此界面下,点击网页上的链接、按键或是F5刷新,可以看到与网页的交互信息。点击相应console下新出现的链接,可直接跳转到对应信息条目下。动态网页这个工具有很大的帮助,更多信息看第4条。控制台下可以输入一些变量函数。
4.动态网页下,console控制台会出现一些链接,注意前面的信息:XHR。它是js进行http通讯的接口,现在也有新的版本,其实现动态刷新的工具。
二、磨刀不误砍柴工
爬虫多是第三方库,里面的一些参数的使用是必须了解其中意义的,不然很容易走弯路,我因此浪费了些时间。所以强烈建议:应该先抽出些时间了解这些常用到的工具的基本知识。
静态网页:静态网页以及少量表单交互的网站可以使用如下的技术路线:
requests + bs4 + re——分别是网页下载、BeautifulSoup提取网页结构信息和正则表达式。这三个为对应python库名,网上相关内容很多。scrapy——是一种爬虫模块,可以配合re一块使用。
二、展望
1. 爬虫系统效率仍然比较低
2. 爬取的信息不够准确
3. 还有很多爬虫算法有待学习和研究
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏




