爬取小姐姐写真照的全站异步爬虫,即使设置了反爬我也要爬给你看
7.3更新:
1,修正了bug,并且现在可以自己选择开始下载页和要下载的页数。
2,打包了我的python运行环境和代码,需要的可以直接下载压缩包,在解压后的文件夹内运行。
pip install -r requirements.txt即可将你的python环境变成同我一样,运行就应该不会出错了。
说在前面:1,因为用的异步方法,食用本爬虫前,请先
pip install aiohttp
pip install aiofiles2,这个网站设置了防盗链以及反爬,网站图片url无法直接访问,自己修改时,请在请求头中加上Referer字段,网站对同一ip的并发访问也有限制,超过7,30秒左右基本就会被暂时禁止访问。所以并发连接数不要太大,7够用了。具体效果看截图。
1、tulishe.py
import asyncio
import random
import time
import aiohttp
import aiofiles
import requests
from lxml import etree
import os
import re
from fake_useragent import UserAgent
from functools import wraps
from asyncio.proactor_events import _ProactorBasePipeTransport
def silence_event_loop_closed(func):
@wraps(func)
def wrapper(self, *args, **kwargs):
try:
return func(self, *args, **kwargs)
except RuntimeError as e:
if str(e) != 'Event loop is closed':
raise
return wrapper
_ProactorBasePipeTransport.__del__ = silence_event_loop_closed(_ProactorBasePipeTransport.__del__)
ua = UserAgent()
headers = {'User-Agent': ua.random, 'Referer': 'http://www.tulishe.com'}
class tulishe:
def __init__(self):
self.write_num = 0
async def get_url(self, url):
async with aiohttp.ClientSession() as client:
async with client.get(url, headers=headers) as resp:
if resp.status == 200:
return await resp.text()
async def html_parse(self, html):
semaphore = asyncio.Semaphore(5)
html_parse = etree.HTML(html)
url_list = html_parse.xpath('//div[@class="img"]//a[@rel="bookmark"]/@href')
tasks = [asyncio.create_task(self.img_parse(url, semaphore)) for url in url_list]
await asyncio.wait(tasks)
async def img_parse(self, h_url, sem):
async with sem:
semaphore = asyncio.Semaphore(5)
h_html = await self.get_url(h_url)
h_html_parse = etree.HTML(h_html)
title = h_html_parse.xpath('//h1[@class="article-title"]/text()')[0]
img_demo_url = h_html_parse.xpath(
'//*[@id="gallery-2"]/div[@class="gallery-item gallery-blur-item"]/img/@src')
img_url_list = []
for d_url in img_demo_url:
img_url = d_url.split('=')[1].split('&')[0]
img_url_list.append(img_url)
i_u_l = h_html_parse.xpath(
'//div[@class="gallery-item gallery-fancy-item"]/a/@href')
full_list = i_u_l + img_url_list
index_list = list(range(1, len(full_list) + 1))
index_dict = dict(zip(full_list, index_list))
tasks = [asyncio.create_task(self.img_con(i_url, i_num, title, semaphore)) for i_url, i_num in
index_dict.items()]
await asyncio.wait(tasks)
async def img_con(self, url, num, title, semaphore):
async with semaphore:
async with aiohttp.ClientSession() as client:
async with client.get(url, headers=headers) as resp:
if resp.status == 200:
img_con = await resp.read()
await self.write_img(img_con, num, title)
else:
print('请求出错,请尝试调低并发数重新下载!!')
async def write_img(self, img_con, num, title):
if not os.path.exists(title):
os.makedirs(title)
async with aiofiles.open(title + '/' + f'{num}.jpg', 'wb') as f:
print(f'正在下载{title}/{num}.jpg')
await f.write(img_con)
self.write_num += 1
else:
async with aiofiles.open(title + '/' + f'{num}.jpg', 'wb') as f:
print(f'正在下载{title}/{num}.jpg')
await f.write(img_con)
self.write_num += 1
async def main(self, ):
q_start_num = input('输入要从第几页开始下载(按Entry默认为1):') or '1'
start_num = int(q_start_num)
total_num = int(input('请输入要下载的页数:')) + start_num
print('*' * 74)
start_time = time.time()
for num in range(start_num, total_num + 1):
url = f'http://www.tulishe.com/all/page/{num}'
html = await self.get_url(url)
print('开始解析下载>>>')
await self.html_parse(html)
end_time = time.time()
print(f'本次共下载写真图片{self.write_num}张,共耗时{end_time - start_time}秒。')
a = tulishe()
asyncio.run(a.main())
2,截图
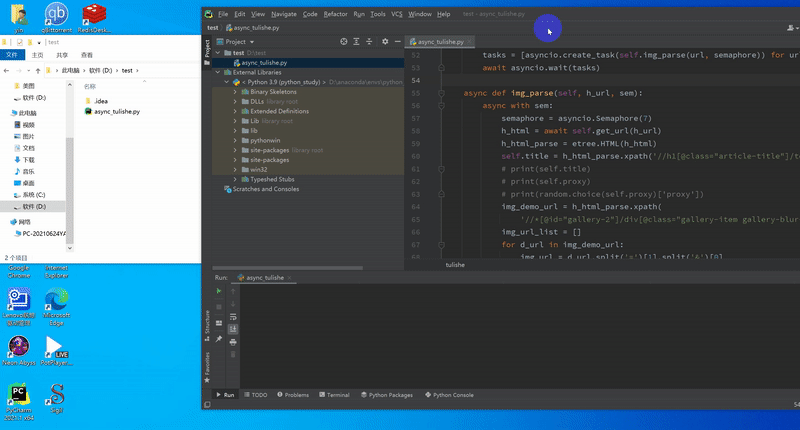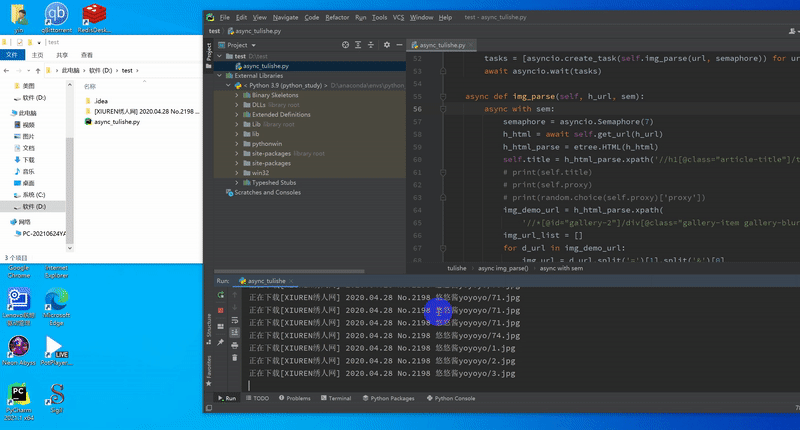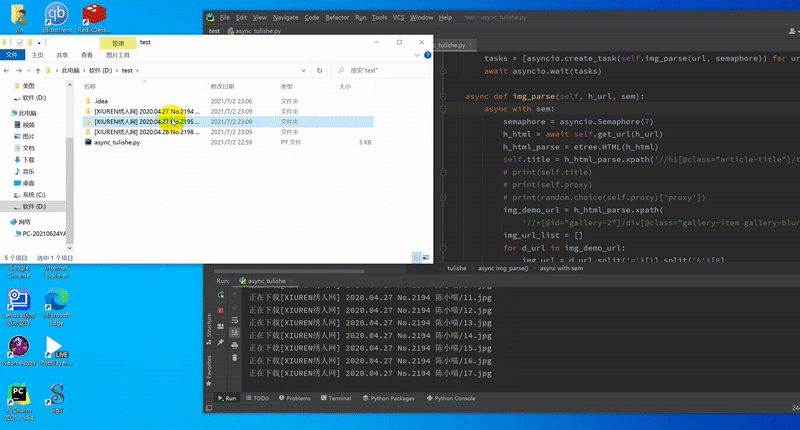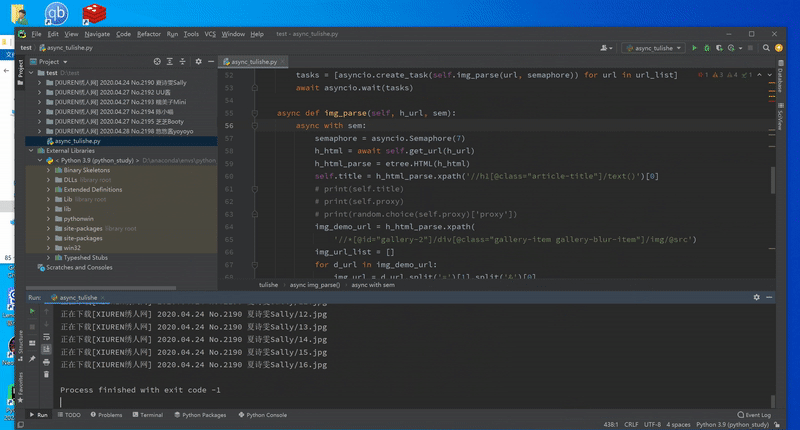
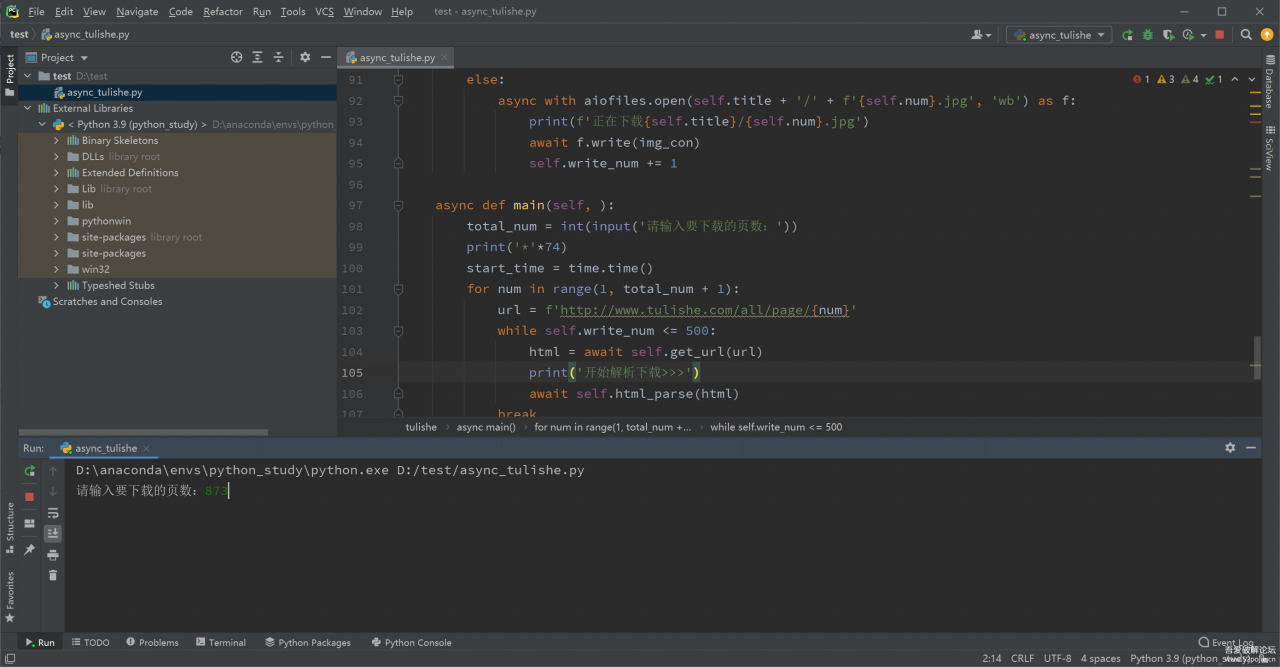
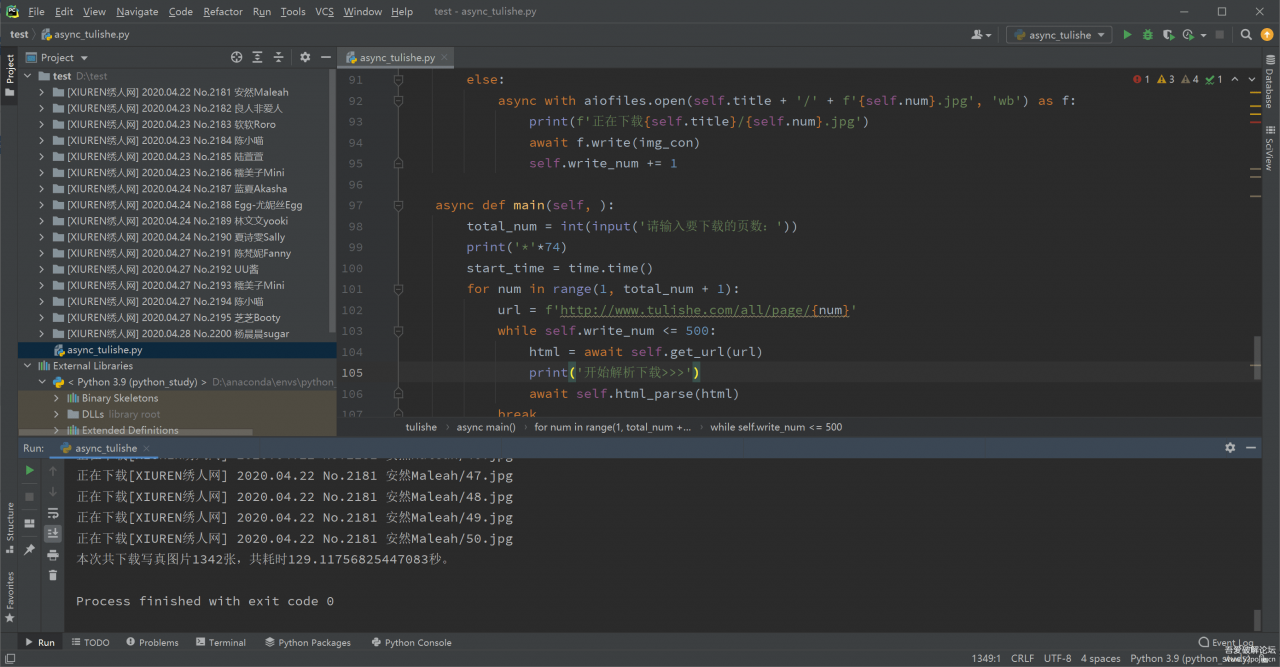
结语:可以看到,虽然有反爬限制,但1秒10张的速度是完全可以实用的,虽然之前想尝试用代{过}{滤}理池规避,但实际实验后发现,免费的完全不靠谱,可用的又太贵,只是用来日常学习实用,还是采用限制并发比较实际。
赞赏
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏

