用python爬取网络图——简单便捷
经常有需求说需要爬取某某网站的某些数据,因为python的包最多的,首先尝试使用python爬~便有了本文
有了python爬网页爬图这项技能,不光能爬数据,爬图,,,嗯~
建议大家在法律范围内做爬虫,毕竟命令是领导下的,锅却要我们来背~
python基本配置
安装pip
通过pip我们可以很方便的通过包名安装其他的python包。在Python 2 >=2.7.9 or Python 3 >=3.4 中已经内置了pip。可以使用如下命令查看是否已安装pip。
python -m pip –version
# output: pip 18.0 from C:UserslenovoAppDataLocalProgramsPythonPython36libsite-packagespip (python 3.6)
如果没有,可以通过下载get-pip.py,并运行如下命令安装:
python get-pip.py
我们可以使用pip安装其他包,如下文需要使用的BeautifulSoup需要我们安装bs4
pip3 install bs4
爬虫常用包
requests
requests是一个处理URL资源很方便的包。
import requests
r = requests.get(‘https://juejin.cn’)
print(r)
print(r.status_code)
print(r.text)
输出结果:
200
Requests: HTTP for Humans
几个常用的样例:
r = requests.get(‘https://xxx’, auth=(‘user’, ‘pass’))
r = requests.post(‘https://xxxx’, data = {‘key’:’value’})
payload = {‘key1’: ‘value1’, ‘key2’: ‘value2’}
r = requests.get(‘https://httpbin.org/get’, params=payload)
print(r.text)
BeautifulSoup
使用Beautiful Soup可以很方便的从html中提取数据。
官方中文文档地址:beautifulsoup.readthedocs.io/zh_CN/v4.4.…
简单的使用样例:
from bs4 import BeautifulSoup
soup = BeautifulSoup(open(“index.html”))
soup = BeautifulSoup(“data”)
# 浏览数据的方式
soup.title
#
soup.title.name
# u’title’
soup.title.string
# u’The Dormouse’s story’
soup.title.parent.name
# u’head’
soup.p
#
The Dormouse’s story
soup.p[‘class’]
# u’title’
soup.a
# Elsie
soup.find_all(‘a’)
# [Elsie,
# Lacie,
# Tillie]
soup.find(id=”link3″)
# Tillie
open函数文件下载
open是python的内置函数,用于打开一个文件,并返回文件对象。常用参数为file与mode,完整参数如下:
open(file, mode=’r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
“””
参数说明:
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式:
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
opener:
“””
开启爬图之路
爬图链接:www.easyapi.com/xxx
这个链接的特点是:
简单,只有一张图片
链接不变,但刷新后图片变化
网页HTML代码与页面展示如图:

我们取其中的重要源码查看:
…

….
刷新页面,会发现img的src路径在编号,但title不变。
因此,我们可以通过来获取这个标签以及src
获取html内容
使用requests获取html内容:
headers = {‘referer’: ‘https://www.easyapi.com/xxx’, ‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0’}
htmltxt = requests.get(res_url, headers=headers).text
查找html中的图片链接
html = BeautifulSoup(htmltxt)
for link in html.find_all(‘img’, {‘title’: ‘欣赏美女’}):
# print(link.get(‘src’))
srcLink = link.get(‘src’)
下载图片
# ‘wb’表示以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
with open(‘./pic/’ + os.path.basename(srcLink), ‘wb’) as file:
file.write(requests.get(srcLink).content)
完整代码
网页图片是随机的,因此我们循环请求1000次,获取并下载图片。完整代码:
import requests
from bs4 import BeautifulSoup
import os
index = 0
headers = {‘referer’: ‘https://www.easyapi.com/xxx/service’, ‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0’}
# 保存图片
def save_jpg(res_url):
global index
html = BeautifulSoup(requests.get(res_url, headers=headers).text)
for link in html.find_all(‘img’, {‘title’: ‘欣赏美女’}):
print(‘./pic/’ + os.path.basename(link.get(‘src’)))
with open(‘./pic/’ + os.path.basename(link.get(‘src’)), ‘wb’) as jpg:
jpg.write(requests.get(link.get(‘src’)).content)
print(“正在抓取第”+str(index)+”条数据”)
index += 1
if __name__ == ‘__main__’:
url = ‘https://www.easyapi.com/xxx/service’
# 其实不需要循环到1000,通过打印链接可以发现,图片名称地址为 xxx/girl(number).jpg,优化方向可以舍弃获取html再获取图片链接
for i in range(0, 1000):
save_jpg(url)
运行效果:
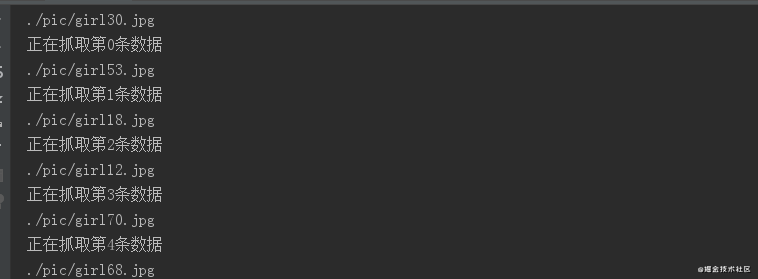
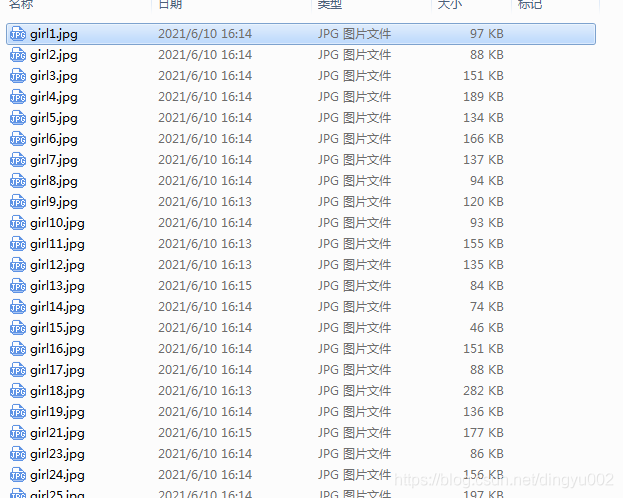
有了这项技能,你不光能爬图片~~
如果觉得文章对你有帮助,麻烦 点赞、评论、收藏 你的支持是我最大的动力!!!
最后小编在学习过程中整理了一些学习资料,可以分享给做软件测试工程师的朋友们,相互交流学习,需要的可以加入我的学习交流群323432957 或加微dingyu-002即可免费获取Python自动化测开及Java自动化测开学习资料(里面有功能测试、性能测试、python自动化、java自动化、测试开发、接口测试、APP测试等多个知识点的架构资料)
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏

