以SD为例分析图片生成原理
世界很神奇,AI很神奇,我们通过一句话就生成了一大段文字,一张图片,一段视频,相信很多朋友听说过SD,听说过comfy UI工作流,今天我们就给大家深入分析一下文生图,图生图的原理。我会尽量用通俗易懂的语言让大家都能明白。
首先,我们添加一段提示词文字生成了一张图片,
过程中其实有三个关键点在起作用,它们分别是:

三个关键节点分别有什么作用呢?
1 大模型
什么是大模型?举个例子,我想让一个小孩在亲戚朋友到访时写出一幅美丽的行楷字,首先他得会,在家时默默地联系,日复一日,年复一年,把行楷,篆体等各种字体都练得炉火纯青,现在你想要他写什么字体他立马就能写出什么字体。这就是他的思想体系里已经有了一个大模型,只要关键词触发,他立马能写出对应的字体。
相信通过这个解释,大家已经懂了什么是大模型,就是生成文字、图片或视频的底层逻辑。
如何获得大模型?
(1)获取训练数据: 获取训练大模型所需的大规模数据集。这些数据集可能来自于公开的数据集、网络上的数据抓取、合作伙伴提供的数据等渠道。数据的质量和多样性对模型的性能至关重要,决定了最终的模型是智能还是智障。
(2)数据预处理: 对获取的数据进行预处理,包括数据清洗、标注、分词、归一化等处理步骤。预处理的目的是为了使数据适合模型的输入格式,并提高模型的训练效果。我们在文本上进行大量标记,比如一个美女图片,标记性别女,头发长,眼睛大,三庭五眼比例,身高,胖瘦,服饰,姿态,手势等等,这些成为Tag.
(3)模型训练: 使用获取的训练数据对选择的AI大模型进行训练。训练过程通常包括多轮迭代,通过优化损失函数来调整模型参数,使模型不断适应训练数据,提高性能。
(4)模型评估: 训练完成后,需要对模型进行评估,以评估其性能和泛化能力。评估通常包括在测试集上进行性能测试、与其他模型进行对比、进行用户反馈等。
(5)模型部署: 完成模型训练和评估后,将模型部署到实际应用中。部署过程涉及将模型集成到软件系统中、优化模型的运行效率、处理实时请求等步骤。
大模型训练流程
1:创建了一个叫做潜在空间的地方 Latent space。
2:用算法把这些图片进行压缩,并高度总结图片的特征,图片保留特征并且压缩成了特征的马赛克,这个过程我们称之为加噪音,特征马赛克也称之为噪音。图片处理后选用模型进行训练,例如常用的模型包括卷积神经网络(CNN)、循环神经网络(RNN)、注意力机制模型等。根据任务的复杂度和数据规模,选择合适的模型进行训练。卷积神经网络卷出图片的特征,跟标签Tag进行对应,相当于他通过大量的阅读资料学习明白了图片特征与文字标签特征tag之间的对应关系。也就是潜在空间中Latent Space中的特征马赛克和他Token对应的这种关系。
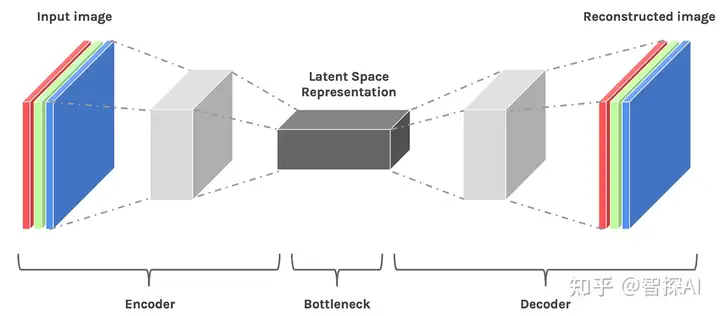
3:文本理解,同时stable diffusion对文本的Tag也进行了总结和压缩,这个过程,称之为Token化。所谓的Token化,就是把文字拆解成小的单位,然后形成各种方便计算机可以理解但是人无法理解的字符字母和符号。
潜在空间里面存放的都是马赛克和文本token的对应关系这个计算的过程一般称之为训练大模型。图片的特征和文本标签以一种压缩和转化后的形式相互对应,使得模型能够基于文本描述生成或理解图像内容。简单理解就是,输入提示词,模型对其进行理解token化就有了特征的标签,就生成对应特征的图片。
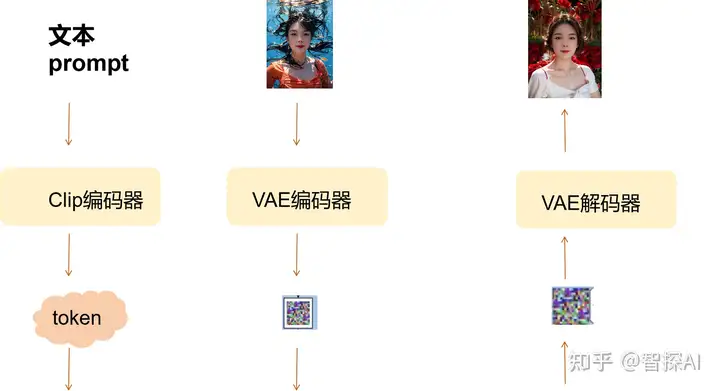
2 Clip和VAE
为了让用户输入的内容可以进入latent space进行匹配,就需要工具把人类可以理解的文字和图片进行编码,转换为可以在Latent Space中工作的标识符,这样才能在潜在空间LatentSpace中进行匹配,文字Prompt在转换的时候需要用到CLIP编码器把Prompt变成Token图片会通过VAE编码器转化成特征马赛克(也就是噪音),最后再经过计算,Stable diffusion 会按照我们想要的意图生成一个新的特征马赛克,这个时候我们需要用VAE解码器,把这个特征马赛克转换为图片,这个图片就是我们最终需要的1 girl 的图片了。
3 采样器
输入的文本提示里的”一个女孩”这样的东西转换成了一个叫”token”的东西。系统会给你搞一个基础特征马赛克0,挺随意的,然后,我们有个采样器,它会把这个”token”和基础特征马赛克0,扔进大模型里,根据提示词token来去噪声,获得一个新特征马赛克1。这个”token”加上基础马赛克0,再加上其他一些东西,我们就管它叫生成约束条件conditioning。例如我们可能会要求图片尺寸,采样模型,迭代步数等等,这个特征马赛克1会跟你输入的”token”继续打交道,搞个小计算,这个计算会一直继续很多次,每次就离计算机认为你要的token结果更近一步,最后到底是啥图形,这个过程叫采样。因为计算了好几次,所以特征马赛克1就会越来越接近真实的图片,所以叫Denose(去噪音)。
采样器用了一个算法和一些设置,跑了N次计算,最后在Latent Space(隐变量空间)中,搞出了一个特征马赛克N,它差不多就是你想要的内容。然后这个马赛克N经过VAE解码器的一顿操作,就变成了真实的图片,整个文生图过程也就这样完成了。
在这个基础上,还能玩出一大堆花样。比如图生图,就是一开始输入的特征马赛克0是根据你输入的图片算出来的;再比如controlnet,就是在采样器的条件里加了更多限制。就是这样,是不是很有意思?
以上就是SD图片生成原理。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏

